에너지 분야는 나노초 또는 밀리초 단위의 시계열 데이터가 빠르게 생성되는 특수한 시장입니다. 시계열 데이터는 금융(Financial) 시장에서부터 중요성이 부각되었으나 이제는 다양한 분야에서 발생하고 이를 활용한 많은 서비스가 만들어지고 있습니다. 최소한 초 단위로 만들어지는 시계열 데이터를 빠르게 등록하고 조회할 수 있는 것을 목적으로하는 시계열 데이터베이스의 입지도 중요해지고 있고 많은 오픈소스 시계열 데이터베이스 솔루션도 만들어지고 있습니다. 현재 조직에서는 해외 금융 분야에서 어느정도 입지를 보이고 있는 시계열 데이터베이스인 KDB+를 도입하여 서비스에 사용중입니다. 라이센스 비용이 생각보다 비싸기는 하지만 고객들이 보유하는 데이터를 빠르게 수집하고 등록하기 위해서는 어쩔수 없는 선택이기도 합니다.
KDB+
What Makes Time-Series Database kdb+ So Fast?
KX Systems의 블로그 또는 Kdb+ and q documentation 사이트에서 제공하는 정보를 토대로 KDB+ 프로세스에 대해서 간단하게 이해하고 활용해볼 수 있습니다. 더 나아가서는 White Paper를 통해서 KDB+ 프로세스를 더 효율적으로 사용하기 위한 방안을 확인할 수 있습니다. 본 글에서는 KDB+ 시계열 데이터베이스를 사용하기 위해 최소한 알아야할 부분을 다룹니다.
데이터베이스 구조
KDB+ 프로세스에서 데이터는 기본적으로 테이블이라는 변수에 저장되며 메모리에 유지됩니다. 그러나, 서버의 메모리 자원은 한정적이므로 모든 데이터를 메모리에 유지하기에는 현실적으로 불가능합니다. KDB+ 프로세스가 사용할 수 있는 메모리가 부족하게되면 'wsfull 오류를 보고하고 프로세스는 종료됩니다. 프로세스가 종료되면 메모리에 저장된 데이터가 모두 유실되므로 이를 보완하기 위한 방법이 필요합니다.
KDB+ 시계열 데이터베이스는 서버 메모리 자원보다 큰 데이터를 저장하기 위해서 디스크 파일을 활용합니다. 테이블의 데이터 규모에 따라 단일 바이너리 파일로 기록하거나 테이블의 컬럼에 대한 데이터를 각 컬럼 이름을 가진 파일을 가지는 폴더로 저장합니다. 더 나아가서는 숫자 또는 날짜와 같은 가상의 파티션을 두어서 더 효율적으로 사용자가 데이터를 쿼리할 수 있도록 지원합니다.
스플레이 테이블
스플레이 테이블(Splayed Table)는 심볼과 같은 기호가 없는 완전히 열거된 테이블이어야합니다. 테이블에 심볼 형식의 컬럼이 존재한다면 Enumerating symbol columns에서처럼 심볼 데이터가 sym 파일이라고하는 별도의 파일에 열거된 상태로 테이블을 저장해야함을 인지해야합니다.
파티션 테이블
일반적으로 KDB+ 프로세스에서 스플레이 테이블을 그대로 사용하기보다는 가상의 파티션 폴더 밑에 두어서 파티션 테이블을 구성하여 로드하도록 구성합니다. 파티션 테이블(Partitioned Table)은 KDB+ 시계열 데이터베이스에서 일반적으로 구성하는 티커플랜트 아키텍처에서 HDB 프로세스를 구성하기 위해서 사용하므로 반드시 이해해야할 부분입니다.
파티션 테이블의 각 스플레이 테이블에 `p# 또는 `g# 속성을 적용하여 저장하는 것은 파일 데이터를 로드하여 사용하는 HDB 프로세스에 대한 쿼리 최적화를 수행할 수 있도록 지원하는 부분으로 필요에 따라 적용해야할 수 있습니다.
프로세스 통신
KDB+ 시계열 데이터베이스는 사용자 요청을 순차적으로 처리하는 단일 스레드를 사용하는 프로세스입니다. 아키텍처적인 관점에서는 단일 프로세스를 실행하여 활용하기보다는 용도와 목적에 맞는 여러개의 프로세스를 실행하고 프로세스 간 통신(IPC)를 통해 서로 유기적인 요청과 응답을 통해 원하는 결과를 제공할 수 있도록 구성하게 됩니다.
일반적으로 다음과 같이 One-shot request 형태로 사용할 수 있습니다.
`::5011 "trade"
`::5011 ({trade};::)다른 프로세스로 다수의 요청을 수행하는 경우에는 hopen 및 hclose를 통해 명시적으로 소켓을 열고 닫는것이 더 효율적입니다. 장시간 소켓을 열어두고 사용하는 것은 다양한 문제를 야기한 경험이 있으므로 개인적으로 추천하지 않습니다.
틱 아키텍처
KDB+ 시계열 데이터베이스를 학습하는 단계에서는 단일 프로세스로도 충분합니다. 그러나, 실제로 시스템을 운용하기 위해서는 다수의 프로세스로 구성된 아키텍처를 도입해야할 필요성이 있습니다. KDB+ 시계열 데이터베이스 시스템을 구성하는 가장 일반적인 아키텍처는 티커플랜트이며 금융 시장에서 사용하기 용이하도록 구성됩니다.
티커플랜트
티커플랜트(Tickerplant)는 데이터를 수집하기 위한 진입점을 제공하는 프로세스로 데이터 등록 함수에 대한 요청을 TP 로그 파일에 기록하여 시스템이 예기치 않은 상황으로 문제가 발생했을 때 복구할 수 있는 방안을 제공합니다. 또한, Pub/Sub으로 데이터 피드 구독자로 등록되어있는 프로세스로 등록된 데이터를 전달하고 삭제함으로써 티커플랜트가 메모리 사용을 최소화할 수 있도록하여 경량 프로세스로 구동됩니다.
실시간 데이터
실시간 데이터베이스(Realtime DB) 프로세스는 티커플랜트 프로세스에 데이터 피드 구독자로 등록되는 클라이언트 중 하나이며 티커플랜트로부터 전달받은 데이터를 메모리에 유지합니다. 그리고 티커플랜트가 전달하는 EOH(End of hour) 또는 EOD(End of day) 이벤트를 받아서 메모리에 유지했던 데이터를 현재 시간 또는 일자에 대한 파티션 테이블로 기록하고 다시 티커플랜트로부터 데이터 수신이 가능하도록 준비합니다.
EOH 또는 EOD 이벤트가 발생하는 시점에는 메모리에 있는 데이터를 파일로 저장해야하므로 데이터 규모에 따라 CPU 연산 및 디스크 I/O 작업에 대한 부하가 야기될 수 있습니다. 따라서, 메모리에 상주되는 데이터의 규모를 예상하고 서버 성능을 결정해야합니다. KDB+ 프로세스가 파일로 기록하는 것은 디스크 I/O 성능에 의존하므로 RDB 프로세스에 대한 병목 현상을 최소화하기 위해서는 높은 I/O 성능을 가지는 스토리지를 고려하는게 좋습니다.
과거 파티션 데이터
과거 파티션 데이터베이스(Historical DB)는 RDB 프로세스가 파티션 테이블 형태의 폴더로 기록한 과거 데이터를 로드하여 사용자 쿼리에 대한 조회 및 결과를 제공할 수 있도록 지원합니다. 데이터 규모 및 서버 자원에 따라 시간 또는 일자별 파티션으로 구성되므로 시스템이 쿼리를 수행하기에 효율적인 구조를 가지도록 고려해야합니다. 예를 들어, 시간별 파티션을 구성하는 경우에는 원하는 기간에 대한 시간 폴더의 데이터만 활용하므로 메모리를 효율적으로 사용할 수 있습니다. 그러나, 사용자 쿼리에 대한 조회 범위가 많아질수록 디스크 I/O 작업을 수행해야하는 비효율적인 부분으로 인해 오히려 조회 시간이 늘어날 수 있습니다.
KDB+ 프로세스는 기본적으로 순차처리임을 인지해야하며 많은 파티션을 조회하는 쿼리가 자주 요청될 가능성이 있다면 하나의 프로세스에서 시간 및 일자별 파티션을 동시에 사용할 수 있도록 지원하지 않으므로 일자별 파티션을 구성하는 별도의 HDB 프로세스를 도입하는 것을 고려해야합니다.
사용자 요청에 대한 쿼리가 여러개의 파티션을 조회해야하는 작업이라면 프로세스 실행 시 지정된 보조 스레드를 통해서 파티션별 조회를 병렬로 수행하도록 프로시저를 작성하여 쿼리 소요 시간을 어느정도는 최적화할 수 있습니다. 꽤 많은 쿼리가 병렬 작업을 수행하는 코드를 도입함으로써 극단적으로 쿼리 수행시간이 줄어듬을 확인할 수 있었습니다. 일반적인 케이스를 예를 들자면 단일 스레드 및 순차 처리에 의해 200ms가 소요되는 프로시저가 병렬 연산 작업 및 비효율적인 반복 작업을 수행하는 방식을 개선하고서 30ms가 소요되도록 개선되었습니다.
개인적인 쿼리 경험에 의하면 데이터 조회에 대한 반복 작업을 최소화하는 것을 고려하고 데이터 조회시에는 병렬 작업을 수행하는 것이 효율적인지를 검토하는게 좋습니다. 그리고 일반적으로 사용되는 키워드 보다 더 적은 시간이나 메모리를 사용할 수 있는 방식을 사용하는 것이 중요합니다.
예를 들어, Left Join을 반복 수행해야하는 경우라면 다음과 같이 연결하여 수행하도록 작성할 수 있습니다.
R:A lj B;
R:R lj C;
R:R lj D;
R:(lj/)(A;B;C;D);장애 및 보완
이제까지 경험했던 장애 또는 현재 경험하고 있는 부분을 공유하고 어떻게 보완할 수 있을까를 정리합니다.
순차 처리로 인한 병목 현상
KDB+ 프로세스는 기본적으로 싱글 스레드로 동작하므로 모든 동기 요청을 순차적으로 처리한다는 제약이 있습니다. 그래서 트랜잭션을 지원하지 않더라도 현재 사용자의 요청에 대한 작업 결과가 다음 요청에 반영됨을 보장합니다. 그러나, 현재 수행중인 요청에 대한 작업이 길어질수록 다른 요청이 대기해야하는 시간이 많아질 수 있습니다. KDB+ 프로세스의 구성이 복잡하고 각 요청에 대한 쿼리가 복잡해짐에 따라서 빠르게 요청되는 쿼리가 순차적으로 밀리는 현상으로 인하여 많은 어려움을 경험하고 있습니다. 사용자 요청에 대한 쿼리 최적화는 일시적인 대안일 뿐이며 결론적으로는 아키텍처적인 관점에서 다음의 정보를 고려해야합니다.
- Multithreaded input queue mode
- Deferred response
- Common design principles for kdb+ gateways
- Query Routing: A kdb+ framework for a scalable, load balanced system
현재 조직에서는 위의 방안들은 검토하였으나 여러가지 제약이나 이해하기 힘든 부분으로 인하여 KDB+ 시스템을 구성하는 각 프로세스에 대한 의존성을 분산하는 작업을 먼저 시도해보기로 결정했습니다. 다수의 프로세스가 서로 유기적으로 통신하면서 발생하는 병목 현상을 최소화하도록 재구성하는게 목적입니다.
단일 디스크 I/O 작업으로 인한 병목 현상
하나의 서버에 KDB+ 프로세스를 여러개 구성하더라도 특정 프로세스에서 디스크 I/O 작업을 수행하는 경우 동일한 폴더나 파일에 대한 작업을 수행해야하는 경우 일시적으로 대기하는 병목 현상이 야기될 수 있습니다. 파티션에 저장된 데이터가 정렬되지 않았다거나 주요 컬럼에 속성이 부여되지 않은 부분을 위해 파티션을 보정하는 프로세스가 작업중일때 동일한 파티션 폴더를 로드해야하는 HDB 프로세스에서 사용자 요청에 대한 작업이 일시적으로 많이 소요되는 문제를 경험했습니다.
티커플랜트 아키텍처에서는 현재 시간 또는 일자에 대한 시계열 데이터가 등록되어야하지만 과거에 대한 시계열 데이터가 실시간으로 등록됨에 따라 올바른 파티션으로 데이터를 병합하는 작업으로 인해 디스크 I/O로 인한 병목 현상이 야기되고 있습니다. 데이터 연동을 시작한 특정 고객이 가지고 있던 과거 데이터를 한번에 등록하게 됨으로써 이로 인해 프로세스에 대한 요청이 느려짐이 보고되고 있습니다.
프로세스 의존성으로 인한 멈춤 현상
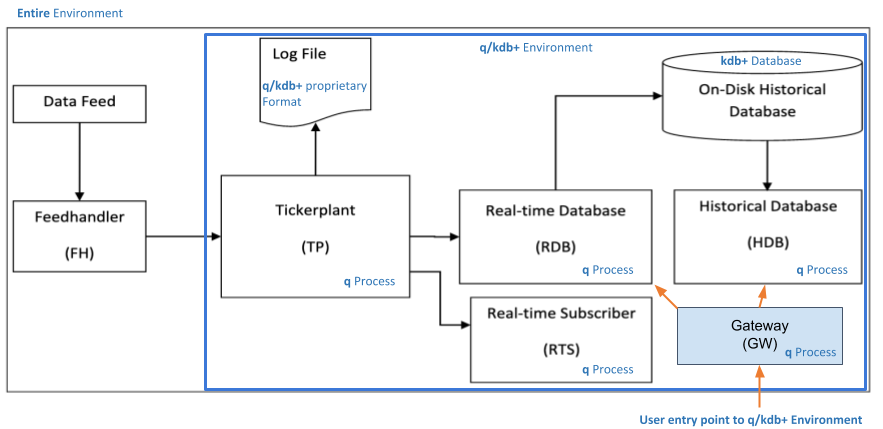
KDB+ 시스템 아키텍처는 다수의 프로세스가 유기적으로 통신하며 시스템을 구성한다고 하였습니다. 간단하게 실행되었던 시스템이 여러가지 이유에 의해서 별도의 프로세스가 추가됨에 따라서 시간 또는 일자별 파티션을 사용하는 HDB 프로세스들이 하나의 RDB 프로세스와 동일한 별도의 프로세스를 의존함에 따라서 서로 요청이 병목되어 프로세스가 요청을 처리중인데도 불구하고 프로세스가 멈추는 것 같아 보이는 현상을 확인했습니다. 각 HDB 프로세스들이 실시간 데이터 조회를 위해서 실시간 데이터를 유지만하는 별도의 읽기 전용 RDB 프로세스를 의존하도록 재구성하였고 이러한 현상이 점차적으로 줄어들고 있습니다.
EOH 다운타임
티커플랜트는 시간 또는 일과가 종료되면 EOH 또는 EOD 이벤트를 데이터 피드 구독자에게 전달합니다. 그리고 특정 RDB 프로세스는 시간 또는 일과 데이터를 현재 파티션에 기록합니다. 프로세스에서 데이터를 파일로 기록하기전에 정렬을 시도하므로 데이터 규모와 서버 성능에 따라서 Downtime이 발생할 수 있습니다. 이러한 다운타임을 최소화하기 위해서 RDB 프로세스에서 데이터를 저장할때는 데이터 정렬이나 스플레이 테이블에 대한 속성 부여를 최소화하고 파티션 보정을 수행하는 별도의 프로세스를 두어서 파티션 데이터를 정렬하고 쿼리 최적화를 위한 컬럼에 속성을 부여하는 작업을 수행하도록 추가 구성했습니다.
실시간 데이터에 과거의 시계열 데이터가 많이 존재할 수 있는 케이스가 발생하면서 파티션을 다시 보정하는 작업을 수행하는 프로세스에 대한 작업도 과중화되는 것을 확인하고 있습니다.
아무리 빠른 성능을 자랑하는 기술이어도 어떤 환경에서 사용되는지와 어떻게 구성하여 사용하는지에 따라서 많은 문제나 제약이 발생할 수 있습니다. 간단했던 시스템이 복잡해지면서 장애가 발생하면 그것을 보완하기 위하여 여러가지 시도를 해보아야합니다. 이전의 경험을 토대로 그럴리 없다, 그럴 가능성은 없다라는 관점은 우리를 힘들게할 수 있습니다. 기술을 사용하는 방식이 동일하지 않음을 인정하고 그것으로부터 야기되는 문제점은 없는지 지속적으로 검토해야합니다. 그것을 우리는 장애 대응 또는 후속 조치라고 말합니다.